Natural Language Processing for Loan Risk
(last updated )
- The story so far
- Exploratory data analysis
- Imputing missing values
- Optimizing data types
- Creating document vectors
- Building the pipeline
- Evaluating the model
- Next steps
The story so far
A few months ago, I built a neural network regression model to predict loan risk, training it with a public dataset from LendingClub. Then I built a public API with Flask to serve the model’s predictions.
Then last month, I decided to put my model to the test and found out that my model can pick grade A loans better than LendingClub!
But I’m not done. Now that I’ve learned the fundamentals of natural language
processing (I highly recommend
Kaggle’s course on
the subject), I’m going to see if I can eke out a bit more predictive power
using a couple of freeform text fields in the dataset: title and desc
(description).
import joblib
prev_notebook_folder = "../input/building-a-neural-network-to-predict-loan-risk/"
loans = joblib.load(prev_notebook_folder + "loans_for_nlp.joblib")
num_loans = loans.shape[0]
print(f"This dataset includes {num_loans:,} loans.")This dataset includes 1,110,171 loans.loans.head()| loan_amnt | term | emp_length | home_ownership | annual_inc | purpose | dti | delinq_2yrs | cr_hist_age_mths | fico_range_low | ... | pub_rec_bankruptcies | tax_liens | tot_hi_cred_lim | total_bal_ex_mort | total_bc_limit | total_il_high_credit_limit | fraction_recovered | issue_d | title | desc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3600.0 | 36 months | 10+ years | MORTGAGE | 55000.0 | debt_consolidation | 5.91 | 0.0 | 148 | 675.0 | ... | 0.0 | 0.0 | 178050.0 | 7746.0 | 2400.0 | 13734.0 | 1.0 | Dec-2015 | Debt consolidation | NaN |
| 1 | 24700.0 | 36 months | 10+ years | MORTGAGE | 65000.0 | small_business | 16.06 | 1.0 | 192 | 715.0 | ... | 0.0 | 0.0 | 314017.0 | 39475.0 | 79300.0 | 24667.0 | 1.0 | Dec-2015 | Business | NaN |
| 2 | 20000.0 | 60 months | 10+ years | MORTGAGE | 63000.0 | home_improvement | 10.78 | 0.0 | 184 | 695.0 | ... | 0.0 | 0.0 | 218418.0 | 18696.0 | 6200.0 | 14877.0 | 1.0 | Dec-2015 | NaN | NaN |
| 4 | 10400.0 | 60 months | 3 years | MORTGAGE | 104433.0 | major_purchase | 25.37 | 1.0 | 210 | 695.0 | ... | 0.0 | 0.0 | 439570.0 | 95768.0 | 20300.0 | 88097.0 | 1.0 | Dec-2015 | Major purchase | NaN |
| 5 | 11950.0 | 36 months | 4 years | RENT | 34000.0 | debt_consolidation | 10.20 | 0.0 | 338 | 690.0 | ... | 0.0 | 0.0 | 16900.0 | 12798.0 | 9400.0 | 4000.0 | 1.0 | Dec-2015 | Debt consolidation | NaN |
5 rows × 69 columns
This post, like its predecessors, was adapted from a Jupyter Notebook, so feel free to fork my notebook on Kaggle or GitHub if you’d like to follow along.
Exploratory data analysis
There isn’t too much exploratory data analysis left to do after how thoroughly
I
cleaned the data
in my first post, but I do have a few quick questions about the title and
desc fields I’d like to answer before I move on.
- How many loans use each field?
- Have these fields always been included in the loan application?
- What is the typical length of each field (in number of words)?
nlp_cols = ["title", "desc"]
loans[nlp_cols].describe()| title | desc | |
|---|---|---|
| count | 1097288 | 71967 |
| unique | 35863 | 70927 |
| top | Debt consolidation | |
| freq | 573992 | 23 |
If the most frequent desc value is empty (or maybe just whitespace), perhaps I
need to convert all empty or whitespace-only values to NaN before continuing.
import re
import numpy as np
for col in nlp_cols:
replace_empties = lambda x: x if re.search("\S", x) else np.NaN
loans[col] = loans[col].map(replace_empties, na_action="ignore")
description = loans[nlp_cols].describe()
description| title | desc | |
|---|---|---|
| count | 1097288 | 71943 |
| unique | 35863 | 70925 |
| top | Debt consolidation | Borrower added on 03/17/14 > Debt consolidat... |
| freq | 573992 | 9 |
Thankfully that didn’t remove too many values, but this “Borrower added on [date]” deal worries me now. I’ll deal with that a little later.
for col in nlp_cols:
percentage = int(description.at["count", col] / num_loans * 100)
print(f"`{col}` is used in {percentage}% of loans in the dataset.")
percentage = int(description.at["freq", "title"] / num_loans * 100)
print(f'The title "Debt consolidation" is used in {percentage}% of loans.')`title` is used in 98% of loans in the dataset.
`desc` is used in 6% of loans in the dataset.
The title "Debt consolidation" is used in 51% of loans.These fields may not be as useful as I had previously thought. Even though there are 35,860 unique titles used across the dataset, 51% of them just use “Debt consolidation”. Maybe the titles are more descriptive in the other 49%?
And the desc field is only used with 6% of loans.
Now to check and see when these fields were introduced.
# `issue_d` is just the month and year the loan was issued, by the way.
loans["issue_d"] = loans["issue_d"].astype("datetime64[ns]")
print("Total date range:")
print(loans["issue_d"].agg(["min", "max"]))
print("\n`title` date range:")
print(loans[["title", "issue_d"]].dropna(axis="index")["issue_d"].agg(["min", "max"]))
print("\n`desc` date range:")
print(loans[["desc", "issue_d"]].dropna(axis="index")["issue_d"].agg(["min", "max"]))Total date range:
min 2012-08-01
max 2018-12-01
Name: issue_d, dtype: datetime64[ns]
`title` date range:
min 2012-08-01
max 2018-12-01
Name: issue_d, dtype: datetime64[ns]
`desc` date range:
min 2012-08-01
max 2016-07-01
Name: issue_d, dtype: datetime64[ns]Neither of these fields were introduced late, but they may have stopped using
the desc field for the last two years of the database.
Now I’ll take a closer look at values in these fields.
import pandas as pd
with pd.option_context("display.min_rows", 50):
print(loans["title"].value_counts())Debt consolidation 573992
Credit card refinancing 214423
Home improvement 64028
Other 56166
Major purchase 20734
Medical expenses 11454
Debt Consolidation 10638
Business 10142
Car financing 9660
Moving and relocation 6806
Vacation 6707
Home buying 5097
Consolidation 4069
debt consolidation 3310
Credit Card Consolidation 1607
consolidation 1538
Debt Consolidation Loan 1265
Consolidation Loan 1260
Personal Loan 1040
Credit Card Refinance 1020
Home Improvement 1016
Credit Card Payoff 991
Consolidate 947
Green loan 626
Loan 621
...
House Buying Consolidation 1
Credit Card Deby 1
Crdit cards 1
"CCC" 1
Loan to Moving & Relocation Expense 1
BILL PAYMENT 1
creit card pay off 1
Auto Repair & Debt Consolidation 1
BMW 2004 1
Moving Expenses - STL to PHX 1
Pay off Bills 1
Room addition 1
Optimistic 1
Consolid_loan2 1
ASSISTANCE NEEDED 1
My bail out 1
myfirstloan 1
second home 1
Just consolidating credit cards 1
Financially Sound Loan 1
refinance loans and home improvements 1
credit cart refincition 1
Managable Repayment Plan 1
ccdebit 1
Project Pay Off Debt 1
Name: title, Length: 35863, dtype: int64Interesting. It seems like there’s plenty of variety in loan titles in the other
49%. A lot of them seem to directly correspond to the purpose categorical
field, but not so many as to make this field useless, I think.
Side note: I discovered at one point when perusing this column that someone entered the Konami Code as the title of their loan application, and their inclusion in this dataset means that the code apparently worked for them—they got the loan.
loans[loans["title"] == "up up down down left right left right ba"][
["loan_amnt", "title", "issue_d"]
]| loan_amnt | title | issue_d | |
|---|---|---|---|
| 1856340 | 12000.0 | up up down down left right left right ba | 2013-04-01 |
loans["desc"].value_counts() Borrower added on 03/17/14 > Debt consolidation<br> 9
Borrower added on 01/15/14 > Debt consolidation<br> 7
Borrower added on 02/19/14 > Debt consolidation<br> 7
Borrower added on 03/10/14 > Debt consolidation<br> 7
Borrower added on 01/29/14 > Debt consolidation<br> 7
..
Borrower added on 01/14/13 > Credit Card consolidation<br> 1
Borrower added on 03/14/14 > Debts consolidation and cash for minor improvements on condominium<br> 1
Borrower added on 03/02/14 > I lost a house and need to pay taxes nd have credit card debt thatI already pay $350 a month on and it goes nowhere.<br> 1
Borrower added on 04/09/13 > I want to put in a conscious effort in eliminating my debt by converting high interest cards to a fixed payment that can be effectively managed by me.<br> 1
Borrower added on 09/18/12 > Want to become debt free, because of several circumstances and going back to school I got into debt. I want to pay for what I have purchased without it having an effect on my credit. That is why I want to consolidate my debt and become debt free!<br> 1
Name: desc, Length: 70925, dtype: int64Do all these descriptions start with “Borrower added on [date]“?
pattern = "^\s*Borrower added on \d\d/\d\d/\d\d > "
prefix_count = (
loans["desc"]
.map(lambda x: True if re.search(pattern, x, re.I) else None, na_action="ignore")
.count()
)
print(
f"{prefix_count:,} loan descriptions begin with that pattern.",
f"({description.loc['count', 'desc'] - prefix_count:,} do not.)",
)71,858 loan descriptions begin with that pattern. (85 do not.)Well now I need to check those other 85.
other_desc_map = loans["desc"].map(
lambda x: False if pd.isna(x) or re.search(pattern, x, re.I) else True
)
other_descs = loans["desc"][other_desc_map]
other_descs.value_counts()Debt Consolidation 2
I would like to pay off 3 different credit cards, at 12%, 17% and 22% (after initial 0% period is up). It would be great to have everything under one loan, making it easier to pay off. Also, once I've paid off or down the loan, I can start looking into buying a house. 1
loan will be used for paying off credit card. 1
This loan will be used to consolidate high interest credit card debt. Over the course of this past year my wife and I had our first child, purchase a home and received a large bonus from work. With the new home and the child on the way I chose to spread my tax withholdings on the bonus to all checks received in 2008 this caused my monthly income to fall by $1500. This in combination with an unexpected additional down payment for our home of $17,000 with only a weeks notice we were force to dip into our Credit Cards for the past several months. Starting January 1, 2009 I will be able to readjust my tax withholding and start to pay off the Credit Card debt we have racked up. This loan will help lower the interest rate during the repayment period and give one central place for payment. My wife and I have not missed a payment or been late for the past 5 years. My fico score is 670 mainly due to several low limit credit cards near their max. I manage the international devision of a software company and my wife is a kindergarten teacher, combined we make 140K a year. Thank you for your consideration and I look forward to working with you. 1
to pay off different credit cards to consolidate my debt, so I can have just one monthly payment. 1
..
Hello, I would like to consolidate my debt into a lower more convenient payment. I have a very stable career of more than 20 years with the same company. My community is in a part of the country that made it through the last few years basically unscathed and has a very promising future.<br>Thank You<br> 1
consolidate my debt 1
I am looking to pay off my credit card debts. 1
This loan is to help me payoff my credit card debt. I've done what I can to negotiate lower rates, but the interest is killing me and my monthly payments are basically just taking care of interest. Paying them off will give me the fresh start I need on my way to financial independence. Thank you. 1
I have been in business for a year and want to eliminate some personal debt and use the remainder of the loan to take care of business expenses. Also lessening the number of trade lines I have open puts me in a better position to pursue business loans since it will be based on my personal credit. A detailed report can be created to show where exactly the funds will go and this can be provided at any time during the course of the loan. 1
Name: desc, Length: 84, dtype: int64It looks like the borrower may be able to add information to the description at different points in time. I should check and see if any of those dates come after the actual issue date of the loan.
from datetime import datetime, date
for row in loans[["desc", "issue_d"]].itertuples():
if not pd.isna(row.desc):
month_after_issue = date(
day=row.issue_d.day,
month=row.issue_d.month % 12 + 1,
year=row.issue_d.year + row.issue_d.month // 12,
)
date_strings = re.findall("\d\d/\d\d/\d\d", row.desc)
dates = []
for string in date_strings:
try:
dates.append(datetime.strptime(string, "%m/%d/%y").date())
except:
continue
for d in dates:
if d >= month_after_issue:
print(f"{row.issue_d} – {row.desc}")
break2014-01-01 00:00:00 – Borrower added on 01/08/14 > I am tired of making monthly payments and getting nowhere. With your help, except for my mortgage, I intend to be completely debt free by 12/31/2016.<br>
2014-01-01 00:00:00 – Borrower added on 01/08/14 > We have been engaged for 2 1/2yrs and wanted to bring out blended family together as one. We are set to get married on 03/22/14 and we are paying for it on our own. We saved the majority of the budget unfortunately there were a few unexpected cost that we still need help with.<br>
2014-01-01 00:00:00 – Borrower added on 01/06/14 > I am getting married 04/05/2014 and I want to have a cushion for expenses just in case.<br>
2014-01-01 00:00:00 – BR called in to push payment date to 09/19/14 because of not having the exact amount of funds in their bank account. Payment was processing. Was able to cancel. It is within grace period.
2014-01-01 00:00:00 – Borrower added on 01/01/14 > This loan is to consolidate my credit cards debt. I made one year this past 11/28/2013 at my current job. I considered to have job security because I'm a good employee. I make all may credit cards payments on time.<br>
2013-05-01 00:00:00 – Borrower added on 04/27/13 > My father passed away 05/12/2012 and I had to pay for the funeral. My mother could not afford it. He was not ill so I could not have planned it. I paid with what I had in my savings and the rest I had to pay with my credit cards. I would like to pay off the CC & pay one monthly payment.<br><br> Borrower added on 04/27/13 > My paerents own the house so I do not pay rent. The utilities, insurance and taxes, etc my mother pays. She can afford that. I help when needed.<br>
2013-02-01 00:00:00 – Borrower added on 02/10/13 > I am getting married in a week (02/17/2013) and have made some large purchases across my credit cards. I would like to consolidate all of my debt with this low rate loan.<br><br> Borrower added on 02/10/13 > I will be getting married in a week (02/17/13) and have had to make some large purchases on my CC. I am financially sound otherwise with low debt obligations.<br>
2012-12-01 00:00:00 – Borrower added on 12/10/12 > Approximately 1 year ago I had a highefficency furnace /AC installed. The installing Co. used GECRB to get me a loan. If I payoff the loan within one year, I pay no interest. The interest rate if not payed by 12/23/2012 is 26.99%. A 6.62% rate sounds a lot better.<br>
2012-11-01 00:00:00 – Borrower added on 11/19/12 > Looking to finish off consolidating the rest of my bills and lower my payments on my exsisting loan. Thanks!!!<br><br> Borrower added on 11/20/12 > Thanks again for everyone who has invested thus far. With this loan it will give me the ability to have only one payment monthly besides utilities and I will be almost debt free by my wedding date of 12/13/14!! Thanks again everyone!<br>
2012-10-01 00:00:00 – Borrower added on 10/22/12 > Need money by 10/26/2012 to purchase property on discounted APR.<br>Good, all of the dates that come after the month the loan is issued only come up because the borrower is talking about a future event.
Now to clean these desc values up a bit I’m going to remove the
Borrower added on [date] >s and the <br>s, since those don’t add value to
the description content.
def clean_desc(desc):
if pd.isna(desc):
return desc
else:
return re.sub(
"\s*Borrower added on \d\d/\d\d/\d\d > |<br>", lambda x: " ", desc
).strip()
loans["desc"] = loans["desc"].map(clean_desc)Imputing missing values
Since only 2% of loans in this set are missing a title, and since most titles
simply copy the loan’s purpose, I’m going to impute missing titles with their
loan’s purpose.
loans["title"].fillna(
loans["purpose"].map(lambda x: x.replace("_", " ").capitalize()), inplace=True
)Since only 6% of loans use a description, I’ll just impute missing descriptions with an empty string. I’m going to wait and include that as a pipeline step a little later, though.
Optimizing data types
I’d really love to get right to the fun part, converting these text fields into document vectors, but I ran into a problem the first several times I tried doing so. Manually adding two sets of 300-dimensional vectors to this 1,110,171-row DataFrame caused its size in memory to skyrocket, exhausting the 16GB Kaggle gives me.
My first attempt to fix this was optimizing my data types, which still didn’t solve the problem on its own, but it’s a worthwhile step to take anyway.
After removing the issue_d column, which is no longer needed, the dataset
contains five types of data: float, integer, ordinal, (unordered) categorical,
and text.
from pandas.api.types import CategoricalDtype
loans = loans.drop(columns=["issue_d"])
float_cols = ["annual_inc", "dti", "inv_mths_since_last_delinq",
"inv_mths_since_last_record", "revol_util", "inv_mths_since_last_major_derog",
"annual_inc_joint", "dti_joint", "bc_util", "inv_mo_sin_rcnt_rev_tl_op",
"inv_mo_sin_rcnt_tl", "inv_mths_since_recent_bc", "inv_mths_since_recent_bc_dlq",
"inv_mths_since_recent_inq", "inv_mths_since_recent_revol_delinq", "pct_tl_nvr_dlq",
"percent_bc_gt_75", "fraction_recovered"]
int_cols = ["loan_amnt", "delinq_2yrs", "cr_hist_age_mths", "fico_range_low",
"fico_range_high", "inq_last_6mths", "open_acc", "pub_rec", "revol_bal",
"total_acc", "collections_12_mths_ex_med", "acc_now_delinq", "tot_coll_amt",
"tot_cur_bal", "total_rev_hi_lim", "acc_open_past_24mths", "avg_cur_bal",
"bc_open_to_buy", "chargeoff_within_12_mths", "delinq_amnt", "mo_sin_old_il_acct",
"mo_sin_old_rev_tl_op", "mort_acc", "num_accts_ever_120_pd", "num_actv_bc_tl",
"num_actv_rev_tl", "num_bc_sats", "num_bc_tl", "num_il_tl", "num_op_rev_tl",
"num_rev_accts", "num_rev_tl_bal_gt_0", "num_sats", "num_tl_120dpd_2m",
"num_tl_30dpd", "num_tl_90g_dpd_24m", "num_tl_op_past_12m", "pub_rec_bankruptcies",
"tax_liens", "tot_hi_cred_lim", "total_bal_ex_mort", "total_bc_limit",
"total_il_high_credit_limit"]
ordinal_cols = ["emp_length"]
category_cols = ["term", "home_ownership", "purpose", "application_type"]
text_cols = nlp_cols
size_metrics = pd.DataFrame(
{
"previous_dtype": loans.dtypes,
"previous_size": loans.memory_usage(index=False, deep=True),
}
)
previous_size = loans.memory_usage(deep=True).sum()
for col_name in float_cols:
loans[col_name] = pd.to_numeric(loans[col_name], downcast="float")
for col_name in int_cols:
loans[col_name] = pd.to_numeric(loans[col_name], downcast="unsigned")
emp_length_categories = ["< 1 year", "1 year", "2 years", "3 years", "4 years",
"5 years", "6 years", "7 years", "8 years", "9 years", "10+ years"]
emp_length_type = CategoricalDtype(categories=emp_length_categories, ordered=True)
loans["emp_length"] = loans["emp_length"].astype(emp_length_type)
for col_name in category_cols:
loans[col_name] = loans[col_name].astype("category")
current_size = loans.memory_usage(deep=True).sum()
reduction = (previous_size - current_size) / previous_size
print(f"Reduced DataFrame size in memory by {int(reduction * 100)}%.")
size_metrics["current_dtype"] = loans.dtypes
size_metrics["current_size"] = loans.memory_usage(index=False, deep=True)
pd.options.display.max_rows = 100
size_metricsReduced DataFrame size in memory by 69%.| previous_dtype | previous_size | current_dtype | current_size | |
|---|---|---|---|---|
| loan_amnt | float64 | 8881368 | uint16 | 2220342 |
| term | object | 73271286 | category | 1110383 |
| emp_length | object | 71853397 | category | 1111197 |
| home_ownership | object | 69841784 | category | 1110700 |
| annual_inc | float64 | 8881368 | float32 | 4440684 |
| purpose | object | 79927721 | category | 1111750 |
| dti | float64 | 8881368 | float32 | 4440684 |
| delinq_2yrs | float64 | 8881368 | uint8 | 1110171 |
| cr_hist_age_mths | int64 | 8881368 | uint16 | 2220342 |
| fico_range_low | float64 | 8881368 | uint16 | 2220342 |
| fico_range_high | float64 | 8881368 | uint16 | 2220342 |
| inq_last_6mths | float64 | 8881368 | uint8 | 1110171 |
| inv_mths_since_last_delinq | float64 | 8881368 | float32 | 4440684 |
| inv_mths_since_last_record | float64 | 8881368 | float32 | 4440684 |
| open_acc | float64 | 8881368 | uint8 | 1110171 |
| pub_rec | float64 | 8881368 | uint8 | 1110171 |
| revol_bal | float64 | 8881368 | uint32 | 4440684 |
| revol_util | float64 | 8881368 | float32 | 4440684 |
| total_acc | float64 | 8881368 | uint8 | 1110171 |
| collections_12_mths_ex_med | float64 | 8881368 | uint8 | 1110171 |
| inv_mths_since_last_major_derog | float64 | 8881368 | float32 | 4440684 |
| application_type | object | 74360578 | category | 1110384 |
| annual_inc_joint | float64 | 8881368 | float32 | 4440684 |
| dti_joint | float64 | 8881368 | float32 | 4440684 |
| acc_now_delinq | float64 | 8881368 | uint8 | 1110171 |
| tot_coll_amt | float64 | 8881368 | uint32 | 4440684 |
| tot_cur_bal | float64 | 8881368 | uint32 | 4440684 |
| total_rev_hi_lim | float64 | 8881368 | uint32 | 4440684 |
| acc_open_past_24mths | float64 | 8881368 | uint8 | 1110171 |
| avg_cur_bal | float64 | 8881368 | uint32 | 4440684 |
| bc_open_to_buy | float64 | 8881368 | uint32 | 4440684 |
| bc_util | float64 | 8881368 | float32 | 4440684 |
| chargeoff_within_12_mths | float64 | 8881368 | uint8 | 1110171 |
| delinq_amnt | float64 | 8881368 | uint32 | 4440684 |
| mo_sin_old_il_acct | float64 | 8881368 | uint16 | 2220342 |
| mo_sin_old_rev_tl_op | float64 | 8881368 | uint16 | 2220342 |
| inv_mo_sin_rcnt_rev_tl_op | float64 | 8881368 | float32 | 4440684 |
| inv_mo_sin_rcnt_tl | float64 | 8881368 | float32 | 4440684 |
| mort_acc | float64 | 8881368 | uint8 | 1110171 |
| inv_mths_since_recent_bc | float64 | 8881368 | float32 | 4440684 |
| inv_mths_since_recent_bc_dlq | float64 | 8881368 | float32 | 4440684 |
| inv_mths_since_recent_inq | float64 | 8881368 | float32 | 4440684 |
| inv_mths_since_recent_revol_delinq | float64 | 8881368 | float32 | 4440684 |
| num_accts_ever_120_pd | float64 | 8881368 | uint8 | 1110171 |
| num_actv_bc_tl | float64 | 8881368 | uint8 | 1110171 |
| num_actv_rev_tl | float64 | 8881368 | uint8 | 1110171 |
| num_bc_sats | float64 | 8881368 | uint8 | 1110171 |
| num_bc_tl | float64 | 8881368 | uint8 | 1110171 |
| num_il_tl | float64 | 8881368 | uint8 | 1110171 |
| num_op_rev_tl | float64 | 8881368 | uint8 | 1110171 |
| num_rev_accts | float64 | 8881368 | uint8 | 1110171 |
| num_rev_tl_bal_gt_0 | float64 | 8881368 | uint8 | 1110171 |
| num_sats | float64 | 8881368 | uint8 | 1110171 |
| num_tl_120dpd_2m | float64 | 8881368 | uint8 | 1110171 |
| num_tl_30dpd | float64 | 8881368 | uint8 | 1110171 |
| num_tl_90g_dpd_24m | float64 | 8881368 | uint8 | 1110171 |
| num_tl_op_past_12m | float64 | 8881368 | uint8 | 1110171 |
| pct_tl_nvr_dlq | float64 | 8881368 | float32 | 4440684 |
| percent_bc_gt_75 | float64 | 8881368 | float32 | 4440684 |
| pub_rec_bankruptcies | float64 | 8881368 | uint8 | 1110171 |
| tax_liens | float64 | 8881368 | uint8 | 1110171 |
| tot_hi_cred_lim | float64 | 8881368 | uint32 | 4440684 |
| total_bal_ex_mort | float64 | 8881368 | uint32 | 4440684 |
| total_bc_limit | float64 | 8881368 | uint32 | 4440684 |
| total_il_high_credit_limit | float64 | 8881368 | uint32 | 4440684 |
| fraction_recovered | float64 | 8881368 | float32 | 4440684 |
| title | object | 82840461 | object | 82840461 |
| desc | object | 46918516 | object | 46918516 |
Creating document vectors
Now the fun part. Wrapping my spaCy document vector
function in a scikit-learn
FunctionTransformer
turned out to be the secret that kept this process within memory limits.
Scikit-learn must just be way better optimized than whatever manual process I
was using (go figure).
import spacy
from sklearn.preprocessing import FunctionTransformer
def get_doc_vectors(X):
n_cols = X.shape[1]
nlp = spacy.load("en_core_web_lg", disable=["tagger", "parser", "ner"])
result = []
for row in X:
result_row = []
for i in range(n_cols):
result_row.append(nlp(row[i]).vector)
result.append(np.concatenate(result_row))
return np.array(result)
vectorizer = FunctionTransformer(get_doc_vectors)Building the pipeline
First, the transformer. I’ll use scikit-learn’s
ColumnTransformer
to apply different transformations to different kinds of data.
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer, make_column_selector
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler
from pathlib import Path
def generate_cat_encoder(col_name):
categories = list(loans[col_name].cat.categories)
if loans[col_name].cat.ordered:
return (
col_name,
OrdinalEncoder(categories=[categories], dtype=np.uint8),
[col_name],
)
else:
return (
col_name,
OneHotEncoder(categories=[categories], drop="if_binary", dtype=np.bool_),
[col_name],
)
Path("../tmp/transformer_cache").mkdir(parents=True, exist_ok=True)
transformer = ColumnTransformer(
[
(
"nlp_cols",
Pipeline(
[
(
"nlp_imputer",
SimpleImputer(strategy="constant", fill_value=""),
),
("nlp_vectorizer", vectorizer),
("nlp_scaler", StandardScaler(with_mean=False)),
],
verbose=True,
),
make_column_selector("^(title|desc)$"),
),
]
+ [generate_cat_encoder(col_name) for col_name in ordinal_cols + category_cols],
remainder=StandardScaler(),
verbose=True,
)This model itself will be identical to my previous model, but I’ll use Keras callbacks and a tqdm progress bar to make the training logs much more concise.
import tensorflow as tf
from tensorflow.keras import Sequential, Input
from tensorflow.keras.layers import Dense, Dropout
from sklearn.model_selection import train_test_split
from tqdm import tqdm
np.random.seed(0)
tf.random.set_seed(1)
class ProgressBar(tf.keras.callbacks.Callback):
def __init__(self, epochs=100):
self.epochs = epochs
def on_train_begin(self, logs=None):
self.progress_bar = tqdm(desc="Training model", total=self.epochs, unit="epoch")
def on_epoch_end(self, epoch, logs=None):
self.progress_bar.update()
def on_train_end(self, logs=None):
self.progress_bar.close()
class FinalMetrics(tf.keras.callbacks.Callback):
def on_train_end(self, logs=None):
metrics_msg = "Final metrics:"
for metric, value in logs.items():
metrics_msg += f" {metric}: {value:.5f} -"
metrics_msg = metrics_msg[:-2]
print(metrics_msg)
def run_pipeline(X, y, transformer, validate=True):
X_train, X_val, y_train, y_val = (
train_test_split(X, y, test_size=0.2, random_state=2)
if validate
else (X, None, y, None)
)
X_train_t = transformer.fit_transform(X_train)
X_val_t = transformer.transform(X_val) if validate else None
model = Sequential()
model.add(Input((X_train_t.shape[1],)))
model.add(Dense(64, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(32, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(16, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(1))
model.compile(optimizer="adam", loss="mean_squared_logarithmic_error")
history = model.fit(
X_train_t,
y_train,
validation_data=(X_val_t, y_val) if validate else None,
batch_size=128,
epochs=100,
verbose=0,
callbacks=[ProgressBar(), FinalMetrics()],
)
return history.history, model, transformerEvaluating the model
import dill
history_1, _, _ = run_pipeline(
loans.drop(columns="fraction_recovered").copy(),
loans["fraction_recovered"],
transformer,
)
Path("save_points").mkdir(exist_ok=True)
dill.dump_session("save_points/model_1.pkl")/opt/conda/lib/python3.7/site-packages/pandas/core/strings.py:2001: UserWarning: This pattern has match groups. To actually get the groups, use str.extract.
return func(self, *args, **kwargs)
[Pipeline] ....... (step 1 of 3) Processing nlp_imputer, total= 0.4s
[Pipeline] .... (step 2 of 3) Processing nlp_vectorizer, total= 1.2min
[Pipeline] ........ (step 3 of 3) Processing nlp_scaler, total= 8.6s
[ColumnTransformer] ...... (1 of 7) Processing nlp_cols, total= 1.3min
[ColumnTransformer] .... (2 of 7) Processing emp_length, total= 0.2s
[ColumnTransformer] .......... (3 of 7) Processing term, total= 0.3s
[ColumnTransformer] (4 of 7) Processing home_ownership, total= 0.3s
[ColumnTransformer] ....... (5 of 7) Processing purpose, total= 0.3s
[ColumnTransformer] (6 of 7) Processing application_type, total= 0.3s
[ColumnTransformer] ..... (7 of 7) Processing remainder, total= 1.3s
Training model: 100%|██████████| 100/100 [23:41<00:00, 14.22s/epoch]
Final metrics: loss: 0.02365 - val_loss: 0.02360# Restore save point if needed
import dill
try:
history_1
except NameError:
dill.load_session("save_points/model_1.pkl")import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
def plot_loss_metrics(history, model_num=None):
for metric, values in history.items():
sns.lineplot(x=range(len(values)), y=values, label=metric)
plt.xlabel("epoch")
plt.title(
f"Model {f'{model_num} ' if model_num else ''} loss metrics during training"
)
plt.show()
plot_loss_metrics(history_1, "1")
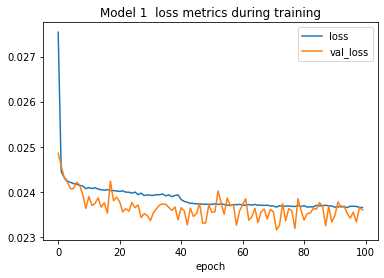
Well, it didn’t overfit, but this model performed a bit worse than my
original, which had settled around a loss of 0.0231. I bet the desc feature is
getting in the way—zeroes spanning 300 columns of the input data on 94% of
the rows is probably quite confusing to the model. I’ll see what happens if I
repeat the process while leaving desc out (making the title vectors the only
new feature of this model compared to my original).
history_2, _, _ = run_pipeline(
loans.drop(columns=["fraction_recovered", "desc"]).copy(),
loans["fraction_recovered"],
transformer,
)
Path("save_points").mkdir(exist_ok=True)
dill.dump_session("save_points/model_2.pkl")/opt/conda/lib/python3.7/site-packages/pandas/core/strings.py:2001: UserWarning: This pattern has match groups. To actually get the groups, use str.extract.
return func(self, *args, **kwargs)
[Pipeline] ....... (step 1 of 3) Processing nlp_imputer, total= 0.1s
[Pipeline] .... (step 2 of 3) Processing nlp_vectorizer, total= 41.3s
[Pipeline] ........ (step 3 of 3) Processing nlp_scaler, total= 4.6s
[ColumnTransformer] ...... (1 of 7) Processing nlp_cols, total= 45.9s
[ColumnTransformer] .... (2 of 7) Processing emp_length, total= 0.2s
[ColumnTransformer] .......... (3 of 7) Processing term, total= 0.3s
[ColumnTransformer] (4 of 7) Processing home_ownership, total= 0.3s
[ColumnTransformer] ....... (5 of 7) Processing purpose, total= 0.3s
[ColumnTransformer] (6 of 7) Processing application_type, total= 0.3s
[ColumnTransformer] ..... (7 of 7) Processing remainder, total= 1.1s
Training model: 100%|██████████| 100/100 [22:26<00:00, 13.46s/epoch]
Final metrics: loss: 0.02396 - val_loss: 0.02451# Restore save point if needed
import dill
try:
history_2
except NameError:
dill.load_session("save_points/model_2.pkl")plot_loss_metrics(history_2, "2")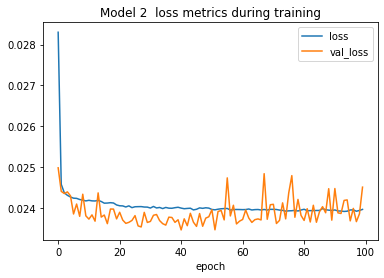
Wow, still not good enough to beat my original model. Just for kicks, I also tried additional runs where I trained for 1,000 epochs, and others where I increased the numbers of nodes in the first two dense layers to 128 and 64. And I tried decreasing the batch size to 64. But still none of these beat my original model. I suppose these text features have no predictive quality to them in terms of loan outcomes. Interesting.
Next steps
If adding these two features decreased predictive capability, then perhaps some of the other variables I was already using are doing the same thing. I should try using some of scikit-learn’s feature selection methods to reduce the dimensionality of the input data.
A more efficient method of hyperparameter optimization would be pretty useful as well. I should give AutoKeras a shot.
Well that was fun! Have any thoughts on how to better integrate language data into the model? I’d love to hear them on Twitter, Mastodon, Facebook, or LinkedIn.
Found an error or typo in this post you’d like to fix? Send me a pull request on GitHub!
Want to publish this article on your blog, in your magazine, or anywhere else? This post, like most of the content on my website, is licensed under a Creative Commons Attribution license, so you’re welcome to share it wherever and however you please, as long as you cite me as the author. I’d also enjoy hearing from you if you do publish this somewhere, but that’s totally up to you.